

در دنیای فناوری اطلاعات، دستیابی همزمان به سرعت بالا و صرفهجویی در هزینه معمولاً چالشی بزرگ محسوب میشود، بهویژه در حوزههایی که نیاز به پردازش فوری دادهها وجود دارد، اما بودجه زیرساختی یا قابلیت مقیاسپذیری محدود است. این تعارض بهطور ویژه در صنایعی نظیر بهداشت و درمان، بازیهای آنلاین، خدمات مالی و تولید محتوای رسانهای مشاهده میشود؛ جایی که دسترسی آنی به حجم بالایی از دادهها امری حیاتی است، اما تهیهی سختافزارهای ردهبالا با هزینهی بالا همیشه امکانپذیر نیست.
در زیرساختهای مدرن فناوری اطلاعات که با بارهای کاری متنوعی مانند مجازیسازی (Virtualization)، پایگاههای داده (Databases) و اشتراکگذاری فایل (File Sharing) مواجه هستند، نیاز به ترکیبی از عملکرد بالا و مقرونبهصرفه بودن امری اجتنابناپذیر است. برای رسیدن به این توازن، بهرهگیری از راهکارهای هوشمند مدیریت داده نظیر Caching و Auto-tiering ضروری است.
راهنمای مطالعه
جهت دریافت مشاوره خرید استوریج با قیمت مناسب و متناسب با نیاز سازمانتان، میتوانید با کارشناسان شرکت رایانش ابری پردیس تماس بگیرید.
رایانش ابری پردیس با بیش از 10 سال سابقه در ارائه خدمات و راهکارهای ذخیره سازی اطلاعات و مشاوره خرید استوریج آماده همکاری با شماست.
دسترسی پویا به فضای ذخیرهسازی داده
ارائه دسترسی سریع به دادههای پرتکرار (Hot Data) بدون فشار بر بودجه برای تهیه فضای ذخیرهسازی پرسرعت و گرانقیمت، یکی از چالشهای دائمی محیطهای فناوری اطلاعات مدرن است. ذخیرهسازی تمامفلش (All-flash Storage) سریع، اما پرهزینه است. اتکا به درایوهای کندتر و مقرونبهصرفهتر مانند HDD، اگرچه باعث صرفهجویی در هزینه میشود، اما عملکرد را قربانی میکند.
راهحل چیست؟ ساخت یک سیستم ذخیرهسازی هیبریدی که ترکیبی از درایوهای پرسرعت و کمهزینهتر باشد. اما صرفاً ترکیب درایوهای سریع و کند کافی نیست؛ بلکه به یک روش هوشمند برای مدیریت محل ذخیرهسازی دادهها در هر لحظه نیاز است.
اینجاست که تکنولوژیهای Auto-tiering و Caching وارد عمل میشوند. این دو راهکار کمک میکنند تا دادههای حیاتی با سرعت بالا در اختیار قرار گیرند، در حالی که اطلاعات با دسترسی کمتر، بهصورت مقرونبهصرفهتری ذخیره میشوند. هر یک از این روشها رویکرد متفاوتی را دنبال میکنند و اگرچه ممکن است در ظاهر مشابه به نظر برسند، اما نقشهای متمایزی در بهینهسازی عملکرد و هزینه ایفا میکنند. درک تفاوت میان آنها، کلید طراحی یک راهکار ذخیرهسازی سریع و کارآمد است.
Auto-tiering چیست؟
Auto-tiering فرآیند جابجایی خودکار دادهها بین سطوح مختلف ذخیرهسازی است. مانند SSDهای پرسرعت، HDDهای میانرده و فضای ذخیرهسازی کند یا آرشیوی که بر اساس میزان دسترسی به دادهها انجام میشود. دادههایی که بهصورت مکرر مورد استفاده قرار میگیرند (Hot Data) به رسانههای سریعتری مانند SSD یا NVMe منتقل میشوند، در حالی که دادههایی که بهندرت مورد استفاده قرار میگیرند (Cold Data) به فضای ذخیرهسازی کندتر و ارزانتری مانند HDD، نوار مغناطیسی (Tape) یا Object Storage ابری منتقل خواهند شد.
این فرآیند کاملاً خودکار است و توسط نرمافزارهای هوشمندی که الگوهای دسترسی را بهصورت پیوسته پایش میکنند، مدیریت میشود؛ بهطوریکه انتقال دادهها بدون نیاز به دخالت دستی انجام میشود. این رویکرد نیاز به مدیریت دستی لایههای ذخیرهسازی را از بین میبرد و موجب افزایش بهرهوری و واکنشپذیری سیستم ذخیرهسازی خواهد شد.
پیشنهاد مطالعه:
نحوه عملکرد Auto-tiering
بر اساس الگوهای دسترسی به داده، سیستم بهصورت خودکار اقدام به مهاجرت دادهها به لایهی مناسب ذخیرهسازی میکند:
- Hot Data → ذخیرهسازی پرسرعت (مانند NVMe یا SSD)
- Warm Data → ذخیرهسازی میانرده (مانند HDDهای ظرفیت بالا یا SSDهای هیبریدی)
- Cold Data → ذخیرهسازی آرشیوی (مانند نوار مغناطیسی (Tape)، (Object Storage یا دیسکهای کندتر)
در هر زمان، تنها یک نسخهی منطقی فعال از هر بلوک داده توسط سیاست Auto-tiering مدیریت میشود. البته، مکانیزمهای محافظت از داده مانند Mirroring یا Erasure Coding ممکن است نسخههای اضافی برای افزایش قابلیت اطمینان یا دوام داده ایجاد کنند، اما این نسخهها خارج از منطق Auto-tiering و بهصورت مستقل مدیریت میشوند.
مزایا و معایب Auto-tiering
مزایا:
- جایگذاری مؤثر بلندمدت دادههای داغ روی ذخیرهساز پرسرعت.
- کاهش بار روی HDD برای فایلهای پرتکرار.
- انتقال دادهها به آرشیو یا فضای ابری هنگام سرد شدن.
معایب:
- تأخیر اولیه در دسترسی: دادهها تنها پس از استفاده مکرر جابجا میشوند.بهعبارتِ دیگر دادهها معمولاً پس از تحلیل آماری الگوهای دسترسی، و بر اساس سیاستهای تعریفشده، به لایههای سریعتر منتقل میشوند.
- فرسایش SSD بهدلیل Write Amplification).Amplification زمانی رخ میدهد که میزان دادهای که واقعاً روی فلش نوشته میشود، از حجم واقعی دادهی اولیه بیشتر باشد که موجب استهلاک سریعتر SSD میشود.)
- پیچیدگی مدیریتی و نیاز به سیاستها.
- ریسک از بین رفتن داده در صورت خرابی SSD بدون Mirror.
عملیات نوشتن در Auto-tiering
هنگام نوشتن دادهی جدید، معمولاً ابتدا روی سریعترین لایه موجود نوشته میشود (برای افزایش عملکرد) و سپس با گذشت زمان یا کاهش دفعات دسترسی، به لایههای کندتر منتقل میشود.
این فرآیند توسط سیاستهای خودکار و پردازشهای پسزمینه مدیریت میشود تا دادههای داغ روی ذخیرهساز سریع باقی بمانند و دادههای سرد به ذخیرهساز کندتر و ارزانتر منتقل شوند.
برای تسریع در عملیات نوشتن، باید از مکانیزمهایی مانند ZFS ZIL/SLOG یا کشهای نوشتاری اختصاصی استفاده کرد، نه Auto-tiering.
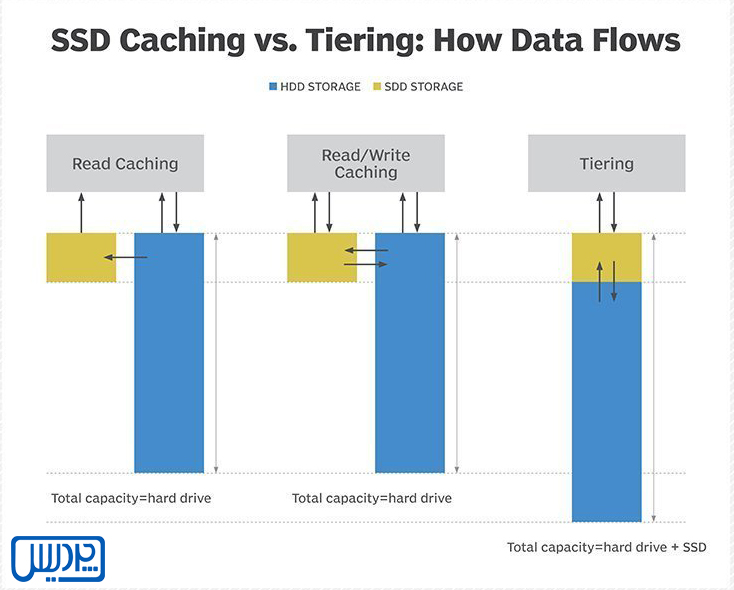
Caching چیست؟
Caching یک نسخه از دادههای پرتکرار را بر روی یک دستگاه ذخیرهسازی سریعتر، مانند RAM یا SSD، نگه میدارد. برخلاف Auto-tiering ،Caching دادهها را جابجا نمیکند، بلکه صرفاً دسترسی به آنها را تسریع میکند در حالی که نسخه اصلی داده همچنان روی مجموعه HDD باقی میماند.
Caching چگونه کار میکند؟
- سیستم ابتدا کش را بررسی میکند.
- در صورت عدم یافتن (Cache Miss)، داده از فضای ذخیرهسازی کندتر خوانده شده و ممکن است برای دفعات بعدی در کش ذخیره شود.
- نسخه اصلی دادهها بهصورت ایمن روی دیسک باقی میماند.
- در فایلسیستمهایی مانند ZFS، برخی عملیات نوشتن هم از Caching بهره میبرند؛ بهویژه در عملیات نوشتن همزمان (Synchronous Write) که توسط SLOG تسریع میشود.
مزایا و معایب Caching
مزایا:
- اولین خواندن ممکن است کند باشد، اما خواندنهای بعدی سریع انجام میشوند.
- ایمنی بالاتر در خرابی بهدلیل وجود نسخه اصلی.
- راهاندازی آسان و بدون نیاز به جابجایی دستی.
- بهینهسازی همزمان خواندن، نوشتن و Metadata.
معایب:
- دادهها در ابتدا به HDD دسترسی پیدا میکنند.
- نیاز به ظرفیت مناسب برای کش دادههای داغ.
- Caching دادهها را به فضای آرشیوی منتقل نمیکند.
پیشنهاد مطالعه:
مقایسه کلیدی Auto-tiering و Caching
| ویژگی | Caching (ZFS) | Auto-tiering |
|---|---|---|
| نحوه مدیریت داده | کپی موقت روی رسانهی سریع | جایجایی فیزیکی دادهها |
| اولین دسترسی | ممکن است کند باشد؛ اما پس از کش، سریع | کند تا زمانی که داده ارتقاء یابد |
| ریسک خرابی | پایین؛ دادهها روی HDD باقی میمانند | بالاتر؛ ممکن است فقط یک نسخه روی SSD باشد |
| فرسایش SSD | Discard حذفهای حداقلی؛ عمدتاً | نوشتنهای پرتکرار برای مهاجرت دادهها |
| راهاندازی و مدیریت | ساده، بهصورت خودکار تنظیم میشود | نیازمند سیاستها و تنظیمات پیچیده |
| عملکرد | پایدار و قابل پیشبینی | متغیر؛ در صورت ماندن داده داغ در لایه سرد، افت عملکرد خواهد داشت |
بدون تردید، مهمترین دغدغهی کاربران، عملکرد (Performance) سیستم ذخیرهسازی است و اینکه Auto-tiering و Caching چگونه آن را تحت تأثیر قرار میدهند.
Auto-tiering برای بارهای کاری با الگوهای مشخص دادههای داغ/سرد بهترین گزینه است، اما ممکن است به دلیل تأخیر در مهاجرت داده و پیچیدگی مدیریتی، عملکرد متغیری ایجاد کند.
Caching در ZFS عملکردی فوری و یکنواخت برای دادههای پرتکرار ارائه میدهد و مدیریت آن آسانتر است، اما برای دستیابی به نتایج بهینه، وابسته به نگهداشتن مجموعه کاری در محدوده کش میباشد.
فایلسیستم ZFS، ذخیرهسازی با رویکرد Cache-First
معماری ZFS که پایه اصلی محصول پرچمدار شرکت Open-E یعنی Open-E JovianDSS محسوب میشود با رویکرد Cache-First یا “اولویت با کش” طراحی شده است. این معماری با بهرهگیری هوشمندانه از حافظه RAM و دستگاههای ذخیرهسازی پرسرعت مانند SSD، دسترسی سریع به دادهها را در اولویت قرار داده و هدف آن افزایش عملکرد، کاهش Latency و کاهش فشار بر روی دیسکهای کندتر است.
با ترکیب چندین لایه پیشرفته کش، ZFS توانسته است معماریای ایجاد کند که هم برای بارهای کاری سنگین و هم برای سناریوهای چندگانه مثل مجازیسازی و فایلسرورها بسیار کارآمد باشد.
| نام کامپوننت | مکان | کارکرد | مزیت | کاربرد |
|---|---|---|---|---|
| (ARC): حافظه کش اصلی در RAM برای دادههای داغ | RAM | کشکردن دادههایی که اخیراً یا مکرراً برای ارائهی سرعت فوقالعاده در خواندن، مورد دسترسی قرار گرفتهاند. | دسترسی آنی به دادههای داغ با سرعت RAM و تشخیص هوشمند الگوهای دسترسی. | لایه پیشفرض کش برای خواندن در تمام سیستمهای ZFS؛ موجب بهبود عملکرد کلی سیستم میشود. |
| (L2ARC): لایه دوم کش در SSD برای دادههای خواندنی بیشتر | SSD | بهعنوان افزونهای برای ARC عمل میکند و دادههای خواندنی بیشتری را فراتر از ظرفیت RAM کش میکند. | پشتیبانی از مجموعه دادههای بزرگتر و حفظ کش حتی پس از ریستارت سیستم (Persistence). | ایدهآل برای بارهای کاری با خواندن سنگین که دادهها از حافظه سیستم بیشتر هستند. |
| (SLOG): بهینهساز عملیات نوشتن همزمان (Synchronous Write) | استفاده از SSD برای پیادهسازی ZIL) ZFS Intent Log) بهمنظور بهینهسازی عملیات نوشتن همزمان (Synchronous Write) | ثبت موقت درخواستهای نوشتن قبل از اعمال نهایی آنها در استخر ذخیرهسازی اصلی. | کاهش Latency در نوشتن همزمان، برای مثال در پایگاه دادهها و ماشینهای مجازی. | حیاتی برای بارهای کاری که به عملیات Fsync وابسته هستند؛ مانند PostgreSQL ،NFS و VMware |
| (ZFS Special Devices): فضای ذخیرهسازی اختصاصی برای Metadata و بلاکهای کوچک | دستگاههای اختصاصی ZFS برای ذخیرهسازی Metadata و بلاکهای کوچک | ذخیرهی Metadata و در صورت نیاز فایلهای کوچک روی رسانههای پرسرعت (مثل SSD) در حالیکه بلاکهای دادهی بزرگ روی HDD باقی میمانند. | حذف نیاز به انتقال Metadata به لایه سریعتر؛ دسترسی سریع و پایدار را تضمین میکند. | مناسب برای File Serverها، محیطهای مجازیسازی و بارهای کاری ترکیبی با تعداد زیاد فایل کوچک. |
کاربرد Caching و Auto-tiering در محیطهای واقعی
در این بخش، نحوه عملکرد دو مکانیزم Caching و Auto-tiering در عمل بررسی میشود و موارد استفاده بهینه از هر یک تشریح خواهد شد.
موارد مناسب برای بهرهگیری از Caching
مدل کش در فایل سیستم ZFS در شرایط زیر بیشترین کارایی را خواهد داشت:
- محیطهای مجازیسازی (نظیر VMware و Proxmox):
استفاده همزمان از ARC (مبتنی بر RAM) و L2ARC (مبتنی بر SSD) امکان مدیریت مؤثر الگوهای ورودی/خروجی متنوع را فراهم میسازد.
- سرورهای پایگاه داده:
بهکارگیری SLOG (ZFS Intent Log) موجب تسریع در عملیات نوشتن همزمان و کاهش محسوس Latency میشود.
نکته: SLOG یک ابزار ثبت نوشتار است و نقش کش خواندن را ایفا نمیکند. - بارهای کاری ترکیبی با عملیات خواندن و نوشتن:
بهرهگیری از ZFS Special Devices بهمنظور ذخیره Metadata بر روی SSD باعث تسریع در دسترسی به دادههای ساختاریافته شده و در عین حال، دادههای حجیمتر روی دیسکهای کندتر باقی میمانند. - سیستمهایی که به عملکرد مشابه SSD نیاز دارند، بدون هزینههای کامل SSD-only:
Caching امکان دستیابی به سرعتی در حد SSD را برای دادههای پرتکرار فراهم میکند، در حالی که دادههای اصلی در فضای ذخیرهسازی مقرونبهصرفهتر حفظ میشوند. - نیاز به بهبود آنی عملکرد برای دادههای پرتکرار (در عملیات خواندن و نوشتن):
کش موجب افزایش لحظهای سرعت دسترسی به دادههایی میشود که بهصورت مستمر در حال استفاده هستند. - زمانیکه مجموعه کاری فعال (Working Dataset) در ظرفیت کش موجود (ARC/L2ARC) جای میگیرد:
در این شرایط، Caching بالاترین سطح بهرهوری را خواهد داشت. - در بارهای کاری لحظهای که نیاز به کاهش Latency بدون جابهجایی فیزیکی دادهها دارند:
کش با حفظ موقعیت فیزیکی دادهها، زمان پاسخدهی را کاهش میدهد.
موارد مناسب برای استفاده از Auto-tiering
مکانیزم Auto-tiering در سناریوهای زیر بیشترین اثربخشی را دارد:
- مدیریت حجم بالای دادهها با الگوهای دسترسی متنوع:
این فناوری با تحلیل خودکار رفتار دسترسی، دادهها را بین سطوح مختلف ذخیرهسازی از جمله SSD ،HDD ،Tape یا Cloud جابهجا مینماید و در نتیجه، توازنی میان عملکرد و هزینه برقرار میسازد. - بهینهسازی جایگذاری دادهها در بلندمدت:
دادههایی که با افزایش دسترسی داغتر میشوند به لایههای سریعتر ارتقاء مییابند و دادههایی که بهمرور زمان سرد میشوند، به لایههای کندتر و ارزانتر منتقل میگردند. - کاهش هزینههای ذخیرهسازی در مقیاس کلان:
با انتقال دادههای کماستفاده یا سرد به فضاهای ذخیرهسازی ارزانتر، هزینه کل ذخیرهسازی بهطور محسوسی کاهش مییابد. - پاسخگویی به الزامات قانونی یا استانداردهای انطباقی مرتبط با محل فیزیکی ذخیرهسازی داده:
Auto-tiering میتواند انتقال دادهها را به سطوح مشخصشده ذخیرهسازی، بر اساس الزامات قانونی، بهصورت خودکار انجام دهد. با این حال، در برخی موارد ممکن است نیاز به کنترل صریح و مستقیم وجود داشته باشد.
چرا Caching در ZFS برنده است؟
Caching در ZFS پویا، هوشمند و مقاوم است. این مکانیزم نیازی به قوانین پیچیده یا فرآیندهای پسزمینه برای جابجایی داده ندارد. بلکه ZFS بهصورت مداوم بار کاری شما را پایش میکند و محتوای کش را برای حفظ عملکرد بالا تنظیم مینماید.
با ترکیب RAM (ARC) ،SSDهای اختیاری (L2ARC و SLOG) و جایگذاری قطعی دادهها (ZFS Special Devices)، ZFS سرعتی پایدار و قابل پیشبینی ارائه میدهد، بدون فرسایش و ریسکهایی که در Auto-tiering سنتی وجود دارد.
اگر در حال ساخت یا نگهداری یک مجموعه ذخیرهسازی داده هستید و به دنبال عملکردی قابل پیشبینی با سربار پایین میباشید، Caching در ZFS هوشمندانهترین و مقیاسپذیرترین مسیر پیشرو است.
سوالات متداول
Auto-tiering یا Caching، کدام یک بهتر است؟
در صورتیکه هدف، بهینهسازی بلندمدت دادهها و کاهش هزینه ذخیرهسازی باشد، Auto-tiering گزینه مناسبتری است. اما برای دستیابی به سرعت فوری در خواندن و نوشتن دادههای پرتکرار، Caching عملکرد بهتری ارائه میدهد.
برای افزایش سرعت سیستم ذخیرهسازی سرور، از چه روشی استفاده شود؟
استفاده از Caching مبتنی بر RAM یا SSD میتواند سرعت دسترسی به دادهها را بهطور قابلتوجهی افزایش دهد، بهویژه در محیطهایی که سیستمفایل ZFS پیادهسازی شده است.
تفاوت Auto-tiering و SSD Cache در چیست؟
SSD Cache نسخهای موقت از دادههای پرتکرار را ذخیره میکند، در حالیکه Auto-tiering دادهها را بهصورت دائمی و هوشمند بین سطوح مختلف ذخیرهسازی جابهجا مینماید.