
در بسیاری از سازمانها، وضعیت زیرساخت فناوری اطلاعات زمانی مشخص میشود که یک اختلال واقعی رخ داده باشد؛ زمانی که یکی از سرورها از دسترس خارج میشود، ارتباط بین شعب قطع میشود یا یکی از سرویسهای حیاتی متوقف میشود. در چنین شرایطی مشخص میشود بخشی از طراحی زیرساخت یا مکانیزمهای High Availability و بازیابی، مطابق انتظار عمل نمیکنند. با پیچیدهتر شدن زیرساختهای سازمانی، صرفاً داشتن Backup، مانیتورینگ یا تجهیزات Redundant دیگر تضمینکننده پایداری سرویسها نیست. آنچه اهمیت دارد، ارزیابی عملکرد واقعی زیرساخت پیش از وقوع بحران است.
راهنمای مطالعه
Chaos Engineering دقیقاً با همین هدف توسعه یافته است. این رویکرد با ایجاد اختلالهای کنترلشده، به تیمهای فناوری اطلاعات کمک میکند میزان تابآوری زیرساخت را ارزیابی کرده و نقاط ضعف پنهان را پیش از تبدیل شدن به یک بحران واقعی شناسایی کنند.
در این مقاله با مفهوم Chaos Engineering، نحوه طراحی آزمایشها، بخشهای قابل ارزیابی و ابزارهای رایج این حوزه آشنا خواهید شد.
Chaos Engineering (مهندسی آشوب) چیست؟
Chaos Engineering (مهندسی آشوب) روشی برای ارزیابی تابآوری سیستمهای نرمافزاری و زیرساختی از طریق ایجاد اختلالهای کنترلشده است. در این رویکرد، شرایطی مانند قطع ارتباط شبکه، از دسترس خارج شدن سرورها، افزایش تأخیر یا خرابی سرویسها شبیهسازی میشود تا رفتار واقعی سیستم بررسی شود.
اما چرا با وجود راهکارهایی مانند High Availability ،Backup و Disaster Recovery، هنوز به Chaos Engineering نیاز داریم؟
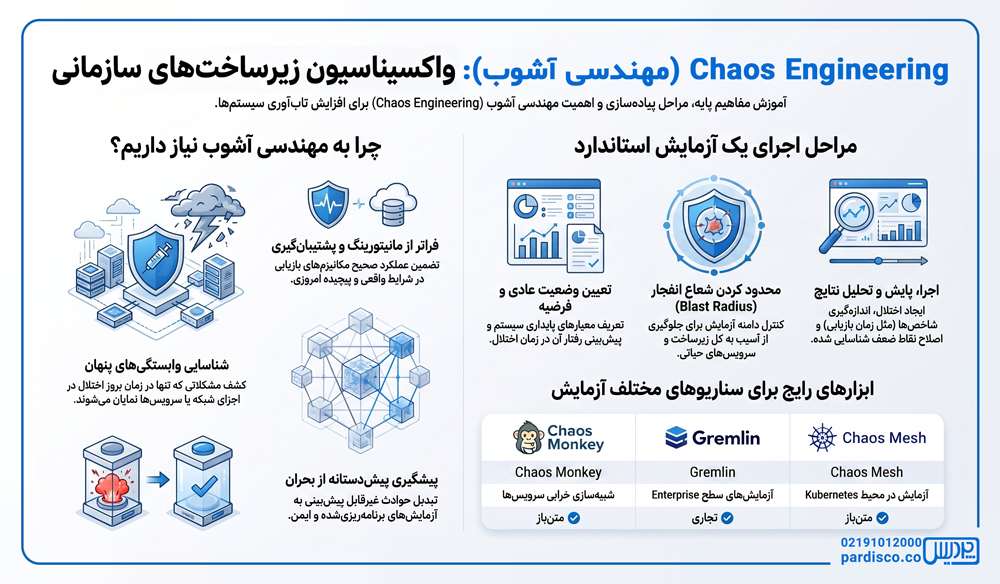
چرا سازمانها به Chaos Engineering نیاز دارند؟
امروزه زیرساختهای سازمانی از اجزای مختلفی مانند شبکه، سرورها، Storage، ماشینهای مجازی و سرویسهای ابری تشکیل شدهاند. خرابی هر یک از این اجزا میتواند بر عملکرد سایر بخشها و در نهایت بر دسترسپذیری سرویسهای حیاتی تأثیر بگذارد.
اگرچه راهکارهایی مانند High Availability ،Backup ،Replication و Disaster Recovery برای افزایش پایداری زیرساخت طراحی شدهاند، اما تا زمانی که در شرایط واقعی آزمایش نشوند، نمیتوان از عملکرد صحیح آنها اطمینان داشت. Chaos Engineering با ایجاد اختلالهای کنترلشده، این امکان را فراهم میکند که نقاط ضعف، وابستگیهای پنهان و مشکلات طراحی پیش از وقوع یک بحران واقعی شناسایی شوند.
پیشنهاد مطالعه:
چه بخشهایی از زیرساخت را میتوان ارزیابی کرد؟
Chaos Engineering به یک فناوری خاص محدود نیست. هر بخشی از زیرساخت که بر دسترسپذیری سرویسها تأثیر میگذارد، میتواند در قالب یک آزمایش کنترلشده ارزیابی شود. جدول زیر، رایجترین بخشهای قابل ارزیابی را نشان میدهد.
| بخش زیرساخت | نمونه آزمایش | هدف |
|---|---|---|
| زیرساخت شبکه | قطع لینک، Packet Loss ،Latency | بررسی Failover و مسیر جایگزین |
| زیرساخت مجازیسازی | قطع ارتباط Host ،vMotion | ارزیابی HA |
| زیرساخت ذخیرهسازی (Storage) | خرابی Controller، قطع Multipath | بررسی تحمل خطا |
| سرویسهای زیرساختی | DNS ،Active Directory | بررسی وابستگی سرویسها |
| محیطهای Cloud و Kubernetes | حذف Pod ،Node Failure | ارزیابی Auto Healing |
بسته به معماری سازمان، ممکن است تنها بخشی از این سناریوها قابل اجرا باشد. انتخاب سناریوها باید بر اساس سرویسهای حیاتی، ریسکهای عملیاتی و اهداف کسبوکار انجام شود. پس از انتخاب بخش موردنظر، نوبت به طراحی آزمایش میرسد.
چگونه یک آزمایش Chaos Engineering طراحی کنیم؟
هر آزمایش Chaos Engineering باید با یک هدف مشخص و فرضیه قابل اندازهگیری آغاز شود. در ادامه، مراحل طراحی یک آزمایش استاندارد را مشاهده میکنید.
گامها:
- تعیین وضعیت عادی سیستم
- تعریف فرضیه
- انتخاب سناریوی اختلال
- محدود کردن Blast Radius
- اجرای آزمایش و پایش
- تحلیل نتایج
خروجیها:
- معیار مقایسه برای تحلیل نتایج
- مشخص شدن رفتار مورد انتظار سیستم
- برنامهریزی برای اجرای آزمایش
- کاهش ریسک و کنترل دامنه تأثیر
- ثبت رفتار سرویسها و زیرساخت
- شناسایی نقاط ضعف و اقدامات اصلاحی
هدف Chaos Engineering، شناسایی نقاط ضعف و بهبود مستمر تابآوری زیرساخت است.
ما در پردیسکو به عنوان ارائهدهنده راهکارهای ذخیرهسازی و امنیت دادههای دیجیتال آمادهایم تا در قالب مشاوره تخصصی و رایگان سازمان شما را همراهی کنیم.
چگونه Chaos Engineering را در زیرساخت سازمانی پیادهسازی کنیم؟
پیادهسازی Chaos Engineering به معنای ایجاد اختلالهای تصادفی در زیرساخت نیست. این رویکرد بر اجرای آزمایشهای برنامهریزیشده و کنترلشده استوار است تا بدون ایجاد ریسک غیرضروری، میزان تابآوری زیرساخت ارزیابی شود.
برای اجرای موفق Chaos Engineering، معمولاً مراحل زیر دنبال میشود:
۱. شناسایی سرویسهای حیاتی: سرویسها و اجزایی که بیشترین تأثیر را بر کسبوکار دارند، مشخص شوند.
۲. انتخاب سناریوی آزمایش: سناریوهایی مانند خرابی Host، قطع لینک شبکه یا از دسترس خارج شدن Storage انتخاب شوند.
۳. محدود کردن Blast Radius: دامنه تأثیر آزمایش کنترل شود تا تنها بخش محدودی از زیرساخت تحت تأثیر قرار گیرد.
۴. اجرای آزمایش و پایش: اختلال ایجاد شده و همزمان عملکرد سرویسها و شاخصهای کلیدی مانیتور شود.
۵. تحلیل و اصلاح: نتایج بررسی شده و اقدامات لازم برای افزایش تابآوری زیرساخت انجام شود.
توصیه میشود نخستین آزمایشها در محیطهای غیرتولیدی یا با Blast Radius محدود آغاز شوند و پس از اطمینان از فرآیندها، بهتدریج در بخشهای بیشتری از زیرساخت اجرا شوند.
هنگام اجرای Chaos Engineering چه شاخصهایی را باید اندازهگیری کنیم؟
برای ارزیابی موفقیت هر آزمایش، باید پیش از اجرا شاخصهای مشخصی تعیین شوند. این شاخصها نشان میدهند اختلال ایجادشده چه تأثیری بر عملکرد زیرساخت و سرویسهای سازمان داشته است.
| شاخص | در Chaos Engineering چه چیزی را ارزیابی میکند؟ |
|---|---|
| میزان دسترسپذیری سرویس (Availability) | میزان تداوم سرویس در زمان وقوع اختلال |
| زمان بازیابی سرویس (Recovery Time) | سرعت بازیابی سرویس پس از اختلال |
| تأخیر شبکه (Latency) | تأثیر اختلال بر زمان پاسخ سرویسها |
| نرخ خطا (Error Rate) | میزان افزایش خطاهای سیستم در طول آزمایش |
| مصرف منابع زیرساخت (CPU / Memory / Disk) | تأثیر اختلال بر مصرف منابع زیرساخت |
| تحقق اهداف RTO و RPO | انطباق فرآیند بازیابی با اهداف RTO و RPO |
این شاخصها نشان میدهند آیا زیرساخت مطابق انتظار عمل کرده است یا خیر. برای اجرای این آزمایشها میتوان از ابزارهای مختلفی استفاده کرد.
ابزارهای رایج Chaos Engineering
ابزارهای متعددی برای اجرای Chaos Engineering وجود دارد. جدول زیر، مهمترین ابزارهای این حوزه را بههمراه کاربرد اصلی آنها معرفی میکند.
| ابزار | کاربرد اصلی | نوع |
|---|---|---|
| Chaos Monkey | شبیهسازی خرابی سرویسها | متنباز |
| Gremlin | اجرای آزمایشهای Enterprise | تجاری |
| Chaos Mesh | آزمایش در Kubernetes | متنباز |
| LitmusChaos | آزمایش Cloud Native | متنباز |
| Azure Chaos Studio | اجرای آزمایشهای Chaos برای منابع Azure مانند Virtual Machine ،AKS، شبکه و سرویسهای ابری | سرویس ابری |
| AWS Fault Injection Service (AWS FIS) | شبیهسازی اختلال در سرویسهای AWS مانند EC2 ،ECS ،EKS ،RDS و شبکه | سرویس ابری |
انتخاب ابزار مناسب به معماری زیرساخت و اهداف آزمایش بستگی دارد. صرفا داشتن ابزار، موفقیت آزمایش را تضمین نمیکند و رعایت چند اصل کلیدی ضروری است.
توصیههای کلیدی برای اجرای Chaos Engineering
| انجام دهید ✔ | انجام ندهید ✖ |
|---|---|
| آزمایش را با Blast Radius کوچک شروع کنید. | کل زیرساخت را یکباره آزمایش نکنید. |
| فرضیه مشخص داشته باشید. | بدون هدف آزمایش نکنید. |
| مانیتورینگ فعال باشد. | بدون پایش آزمایش را اجرا نکنید. |
| نتایج را مستند کنید. | فقط به اجرای آزمایش اکتفا نکنید. |
جمعبندی
Chaos Engineering با ایجاد اختلالهای کنترلشده، به سازمانها کمک میکند تابآوری واقعی زیرساخت را ارزیابی کرده و نقاط ضعف را پیش از وقوع بحران شناسایی کنند. این رویکرد مکمل High Availability ،Backup و Disaster Recovery است و دید دقیقتری از آمادگی زیرساخت در شرایط بحرانی ارائه میدهد.
پرسشهای متداول
- آیا Chaos Engineering فقط برای شرکتهای بزرگ مناسب است؟
خیر. هر سازمانی که از زیرساخت مجازی، Storage ،Kubernetes یا معماری High Availability استفاده میکند، میتواند متناسب با اندازه زیرساخت خود از Chaos Engineering بهره ببرد. - آیا اجرای Chaos Engineering باعث ایجاد اختلال در سرویسها میشود؟
هدف Chaos Engineering ایجاد خرابی نیست، بلکه اجرای اختلالهای کنترلشده با دامنه محدود است. این آزمایشها معمولاً ابتدا در محیط آزمایشی اجرا میشوند و در صورت نیاز، با کنترل کامل در محیط عملیاتی انجام خواهند شد. - تفاوت Chaos Engineering با Disaster Recovery چیست؟
Disaster Recovery مجموعهای از فرآیندها و راهکارها برای بازیابی سرویسها پس از وقوع بحران است، در حالی که Chaos Engineering روشی برای ارزیابی عملکرد همین راهکارها پیش از وقوع بحران محسوب میشود.
به بیان دیگر، Chaos Engineering جایگزین Disaster Recovery نیست، بلکه میزان آمادگی آن را ارزیابی میکند. - آیا Chaos Engineering جایگزین High Availability و Backup میشود؟
خیر. راهکارهایی مانند High Availability ،Backup ،Replication و Disaster Recovery برای افزایش دسترسپذیری و حفاظت از دادهها طراحی شدهاند، اما Chaos Engineering بررسی میکند که آیا این راهکارها در شرایط واقعی مطابق انتظار عمل میکنند یا خیر. - هر چند وقت یکبار باید آزمایشهای Chaos Engineering انجام شوند؟
زمان مشخصی برای همه سازمانها وجود ندارد، اما توصیه میشود پس از هر تغییر مهم در زیرساخت، ارتقای تجهیزات، تغییر معماری شبکه یا پیادهسازی سرویسهای جدید، آزمایشهای Chaos Engineering دوباره اجرا شوند. همچنین اجرای دورهای این آزمایشها میتواند به شناسایی تغییرات ناخواسته در زیرساخت کمک کند. - آیا Chaos Engineering فقط برای Kubernetes کاربرد دارد؟
خیر. اگرچه ابزارهایی مانند Chaos Mesh و LitmusChaos برای Kubernetes توسعه یافتهاند، اما Chaos Engineering محدود به این محیط نیست و در شبکههای سازمانی، زیرساختهای مجازی، Storage، پایگاههای داده، سرویسهای Cloud و معماریهای Hybrid نیز کاربرد دارد.