گروهی از پژوهشگران در دانشگاه واشنگتن سیستمی را با استفاده از یادگیری عمیق Deep Learning ایجاد کرده اند که از نوارهای صوتی استفاده کرده و آن را با حرکت لبها در یک ویدیو هماهنگ می کند.
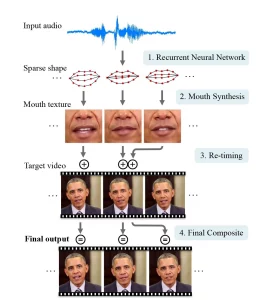
آنچه که در این ویدئو مشاهده می کنید ترکیبی غیر قابل باور از صدا و تصویر است. صداهای به کار گرفته شده از مصاحبه ها و جلسات سخنرانی متعددی استخراج شده و به واسطه یادگیری عمیق منجر به تولید ویدئوهایی شده است که نشان می دهد اوباما در این ویدئو در حال گفتن این کلمات است.
در حالی که چنین نیست!!!